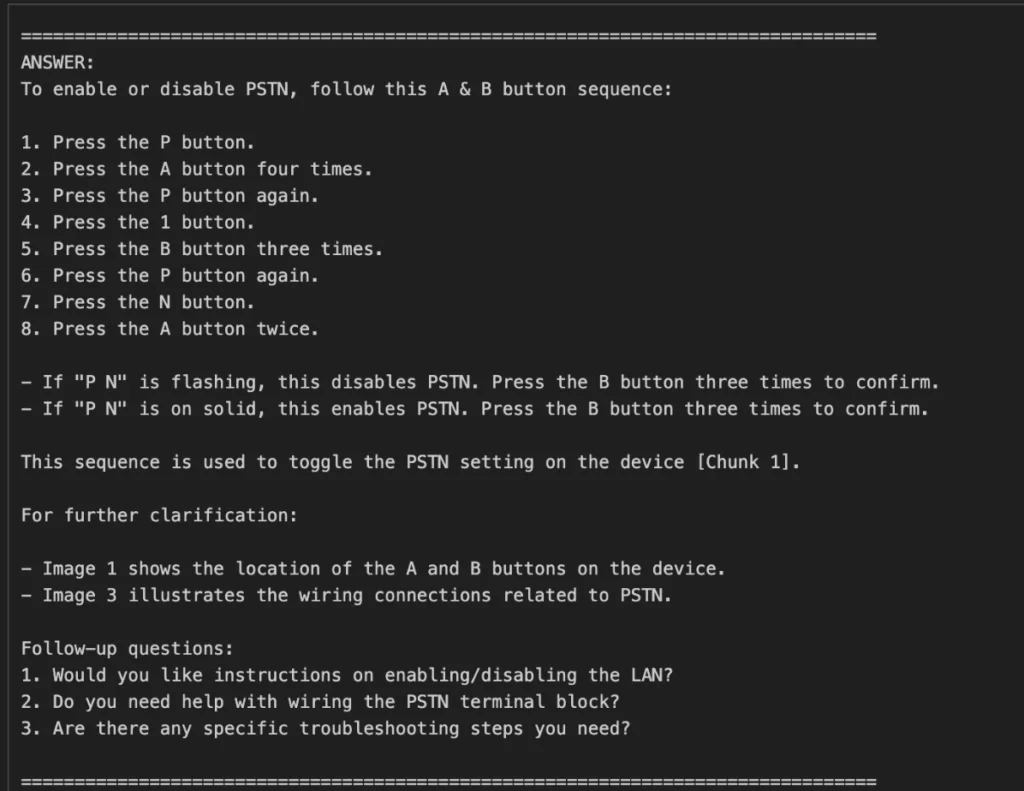
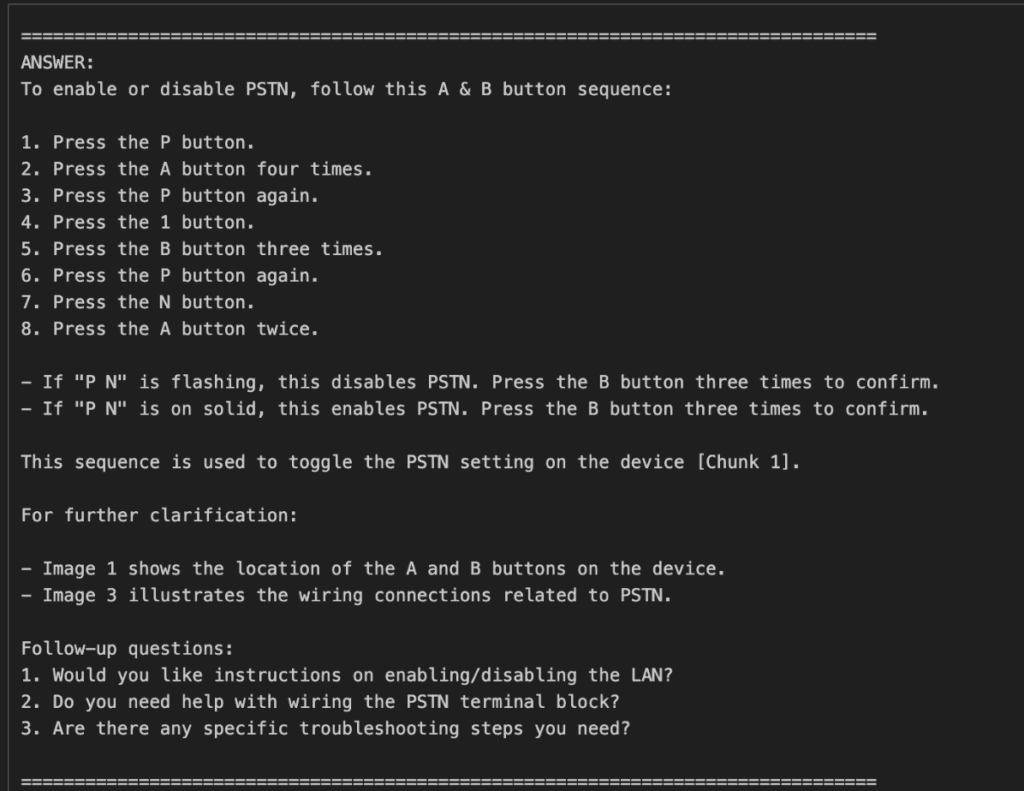
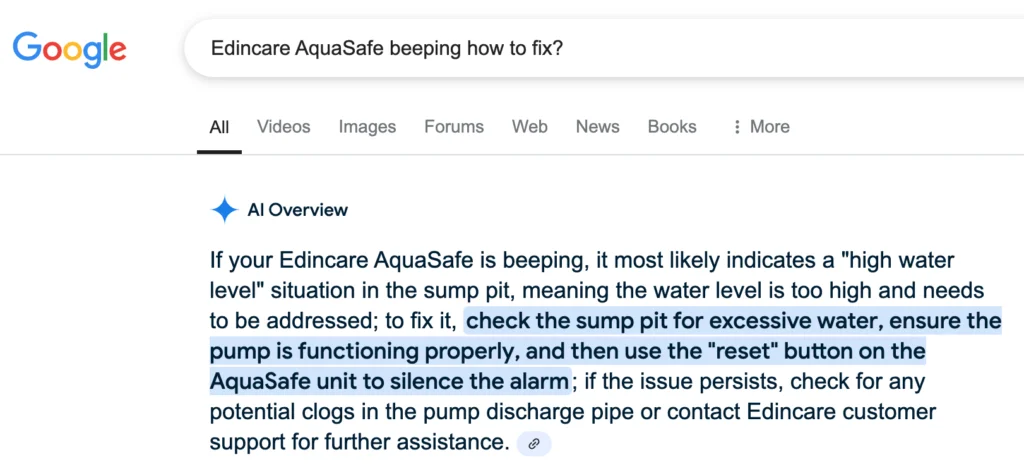
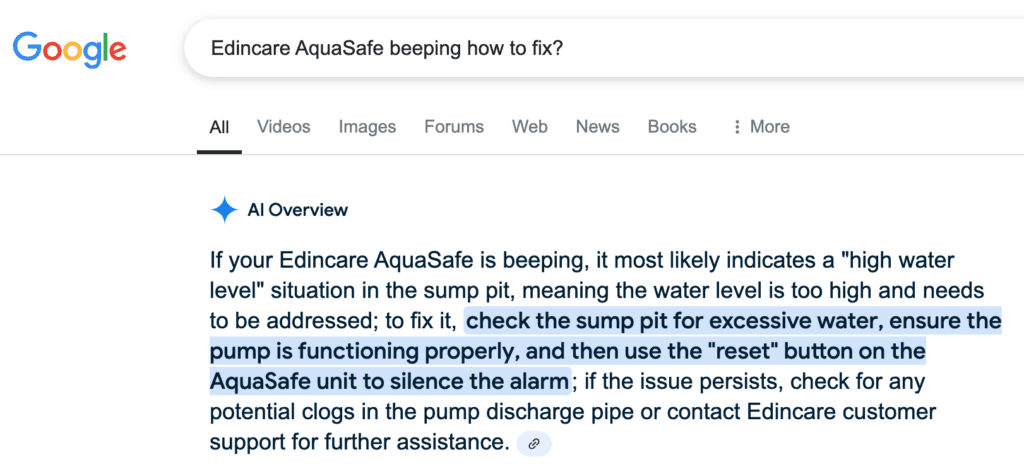
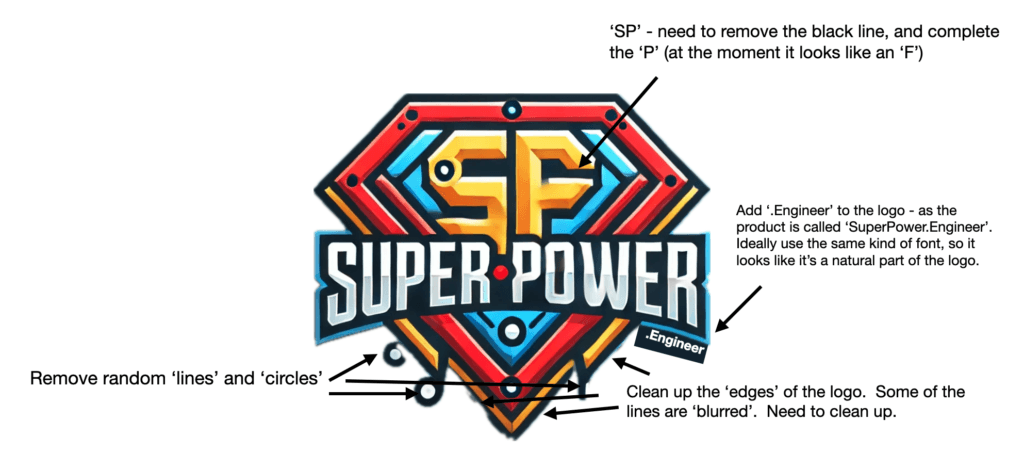
As the highly anticipated engineers' conference rapidly approaches on the 24th of this month, our team is buzzing with excitement and dedicated efforts, steadily moving forward to unveil our groundbreaking AI-powered assistant, SuperPower.Engineer.
This blog post gives an in-depth look into our recent developments, showcasing the significant innovations, technical advancements, and enhancements we've achieved . . .
Bringing Ideas to Life: Interactive Dummy UI
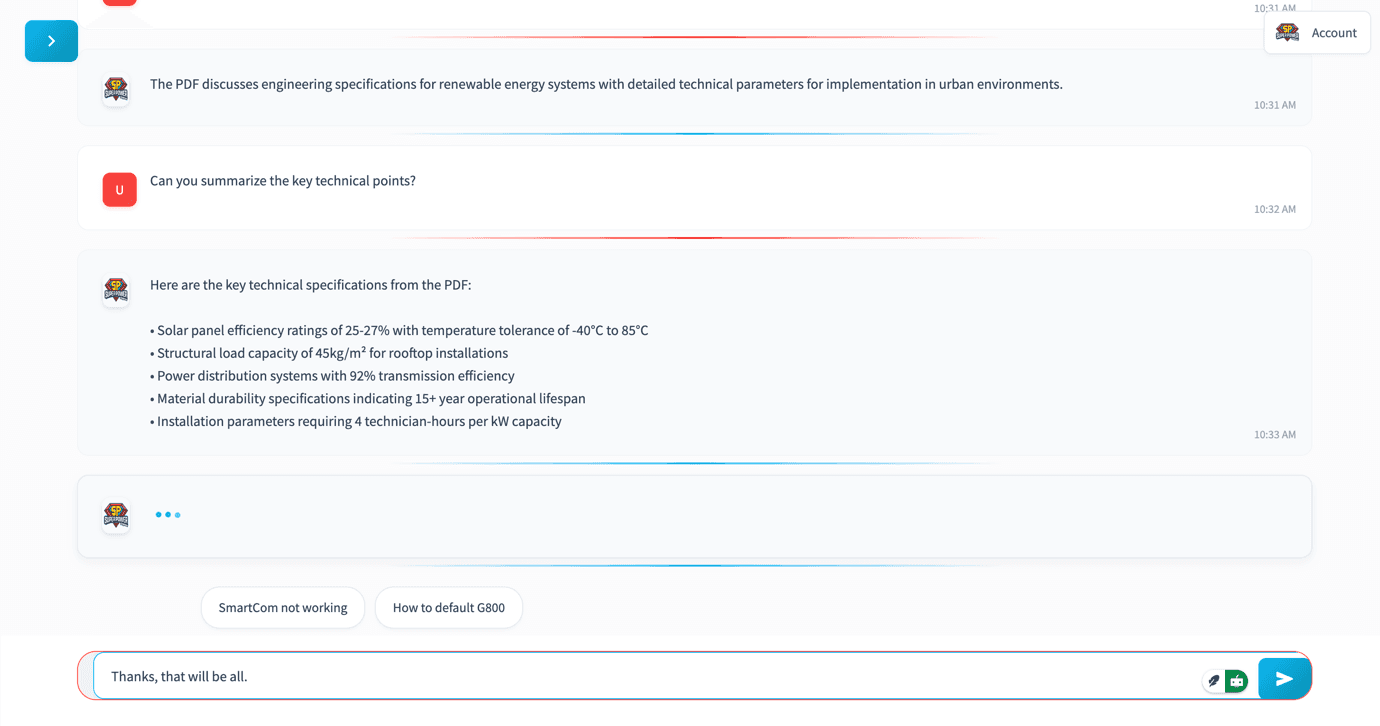
To give life to our vision, we developed an engaging and interactive dummy user interface using Streamlit. This rapid prototyping strategy enabled our team to experiment extensively, iteratively refining and optimising the interface.
Through continuous testing and feedback, we've created a seamless and intuitive user experience, closely aligning with real-world user expectations.
Our dummy / prototype UI has proven instrumental in identifying potential usability issues early, allowing us to enhance user interaction flows significantly before the final implementation.
Meme Magic: AI with a Sense of Humour
Injecting personality and creativity into our AI assistant, we introduced an engaging "Meme Mode," comprising 20 thoughtfully crafted, humorous prompts. This feature showcases Superpower’s playful side, adding an engaging dimension to user interactions.
The addition of Meme Mode underscores our commitment to providing a multifaceted AI experience that resonates with users, making interactions memorable, enjoyable, and relatable. This element of fun helps establish deeper user connections, fostering loyalty and satisfaction.

Deep Web Diving: Advanced Web Scraper
Understanding that a comprehensive knowledge base is fundamental to AI accuracy, our team developed a sophisticated web scraper capable of navigating through multiple layers of web pages.
This advanced scraper effectively captures detailed HTML content and extracts embedded PDFs, substantially enriching our assistant's knowledge repository.
The depth and breadth of data gathered enable Superpower to deliver precise, well-rounded, and highly informed responses, significantly improving its practical utility for users across diverse contexts.

Memory Mastery: DynamoDB Integration
Recognising the vital role of context in conversational AI, we implemented an advanced memory management system utilizing DynamoDB. This robust solution reliably tracks usernames, user IDs, conversation IDs, and chat session data, enhancing the continuity and personalization of user interactions.
By meticulously integrating user IDs and comprehensive session tracking, we've ensured that returning users experience seamless conversations, maintaining relevant context across multiple interactions.
This ensures a personalised, intuitive, and cohesive experience each time a user engages with our AI.
Seamless Session Integration: User ID and Chat Sessions
To further enhance personalisation and continuity, we've seamlessly integrated user ID and chat session tracking. This integration allows Superpower to recall previous interactions effortlessly, delivering context-aware, relevant, and personalised conversations.
Such an intuitive approach significantly improves user satisfaction, creating a consistently engaging and meaningful conversational experience. It also enables robust analytics, helping our team refine and continuously improve the AI’s performance and user interactions.
With the demo day fast approaching, excitement within our team continues to soar. Each accomplishment and innovation brings us one step closer to presenting an exceptional demonstration of Superpower's cutting-edge capabilities.
We’re confident our AI assistant will leave a lasting impression, showcasing the profound potential of technology-driven solutions. Stay tuned as we finalise our preparations—an extraordinary experience awaits!