

Team News
May 18, 2025
Dev Team Progress update - Part 1
Out of the gate we've primarily focused our resources on working out how to retrieve the most accurate answers possible from complex instruction manuals (our core product goal), by extracting & matching chunks of both text and image information - including the ability to extract an understanding of content embedded in images (which is - we found - a pretty complex challenge).
Key progress to date includes:
Document Processing and RAG Pipeline Development:
Focused on refining document processing capabilities for a Retrieval-Augmented Generation (RAG) pipeline.
Conducted research and integrated a data structuring system to improve document parsing and processing - supporting data inputs from Amazon S3, with data storage in Pinecone vector database.
Enhanced data parsing by enabling:
Image extraction for detailed content descriptions.
Table extraction for structured data representation.
Implemented text chunking to improve similarity matching in the vector database.
Utilized OpenAI’s text-embedding-3-large model for vector embedding.
RAG Pipeline Creation:
Built and tested a RAG model and pipeline using Pinecone’s API and GPT-4o for answer generation.
Initial results demonstrated the pipeline's strong performance.

Following a review of the initial results we identified we were consistently generating accurate answers from in-depth complex manuals (which was the good news), however we needed to include wider contextual information to enrich and support the answers (e.g. including citations and more accurate / contextual image information).
Features & testing that followed included:
Citation Integration:
Incorporated source citations directly into LLM inputs to embed accurate citations within generated responses.
Enhanced the transparency, credibility, and traceability of the responses.
Detailed Source Referencing:
Extracted detailed metadata from Pinecone, including document IDs and specific page numbers.
Organized related documentation into an Amazon S3 bucket for easy access to original source PDFs.
Enabled users to verify facts by referencing the exact source pages.
Visual Guidance via Images:
Attempted to display images from referenced pages but faced limitations with metadata and base64 encoding.
Acknowledged the need for improved visual aids for complex questions (e.g., wiring diagrams) and planned for future refinement of this feature.
Incorporation of Internal Knowledge:
Integrated a structured dataset from a CSV file into the pipeline, including specific private knowledge sets like:
Terminology
Expert internal troubleshooting knowledge
Improved the quality of generated responses by enriching them with highly accurate, contextually relevant internal knowledge.
Natural follow-up questions:
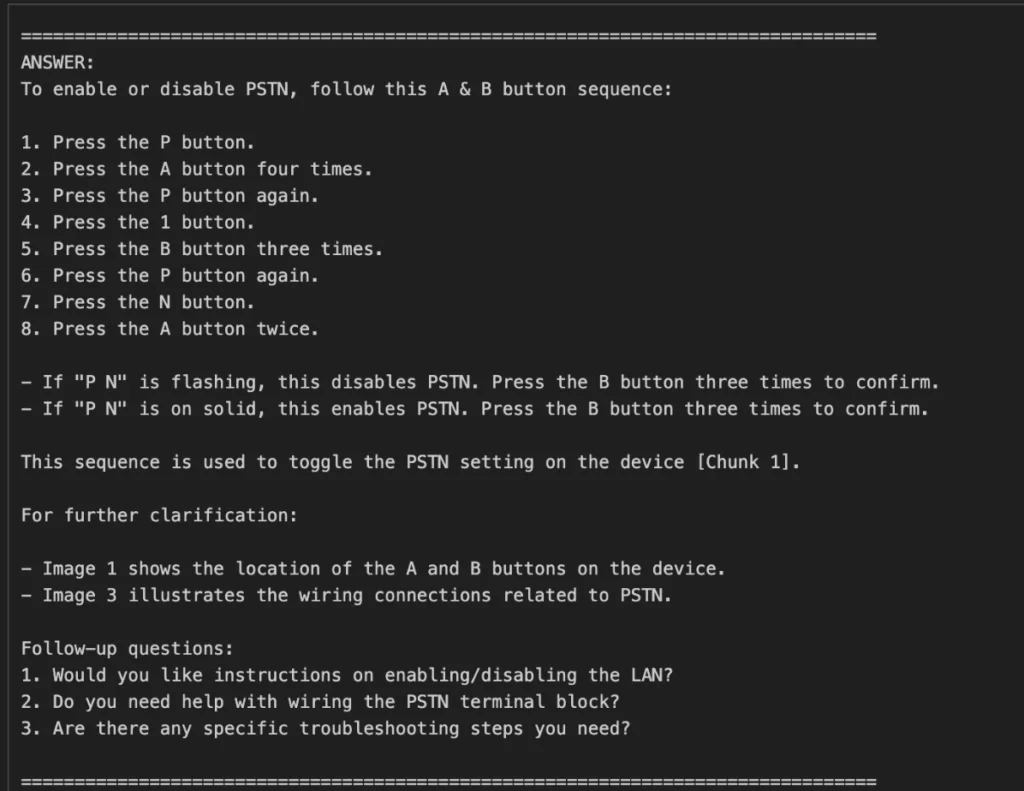
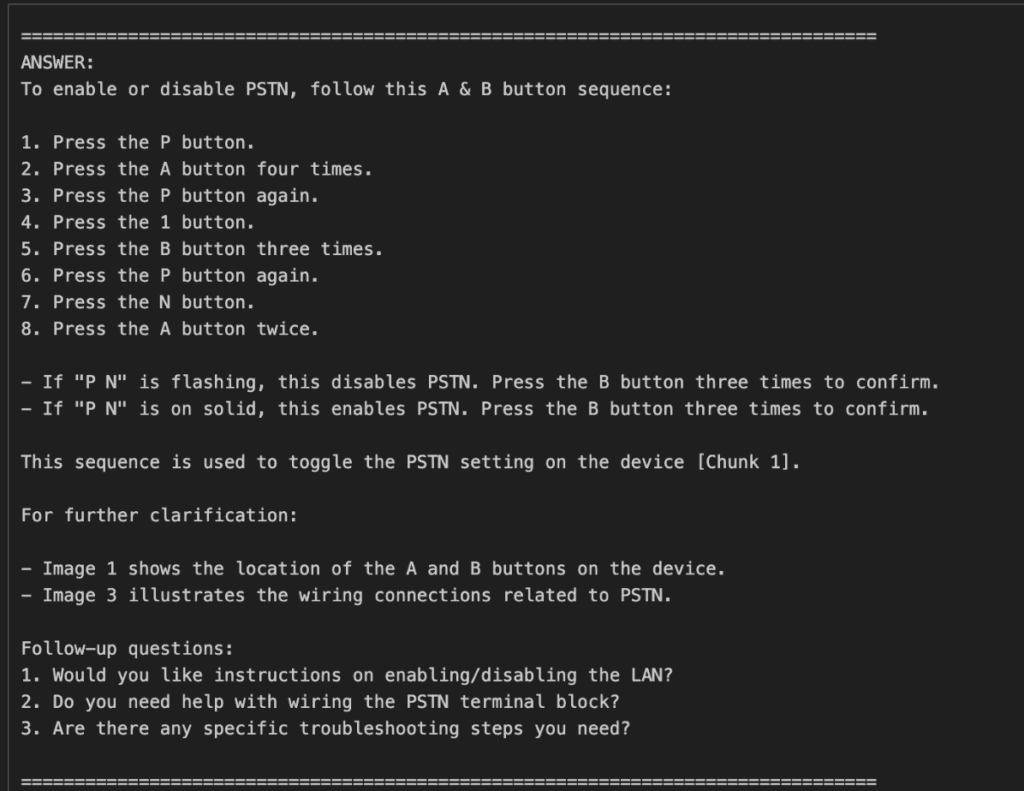
Added x3 follow-up questions per query, to dig deeper into the solution, for example, when programming is described at a top-level, the option to get the step-by-step programming information is provided.
Having made good progress retrieving accurate answers and providing citations (text and image) to help contextualise the answer, we're now moving onto dealing with more 'complex queries' - i.e. system-based queries that may involve more than a single 'instruction manual answer call', and involve various elements of more complex troubleshooting.
Hang tight for more progress and the next update - it's starting to get interesting ;)
Blogs
